

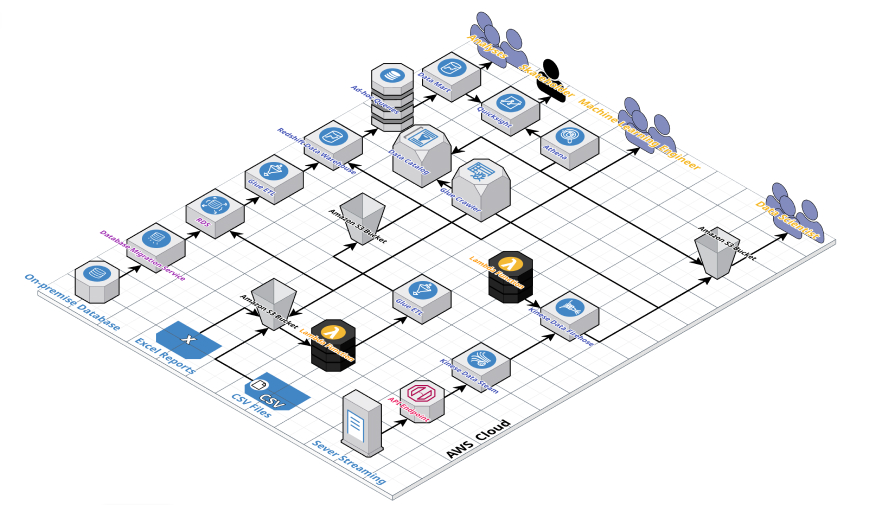
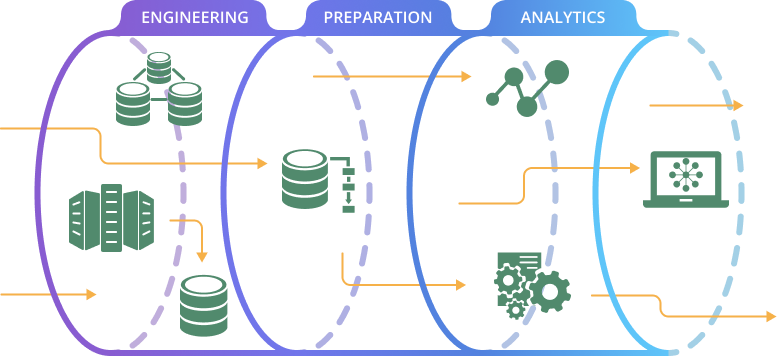



Design and manage scalable data architectures for storing and processing large datasets.
-
JAVA Project Courses
JAVA Project Courses
-
 Java Full Stack Program CourseThe Java Full Stack Program Course helps you fully grasp the development techniques of industrial projects and learn some advanced techniques such as Java SE, Spring Boot, Web development, and Distributed Architecture. You will also gain hands-on experience with real-world Java programs and enhance your resume, which will help you secure your dream job
Java Full Stack Program CourseThe Java Full Stack Program Course helps you fully grasp the development techniques of industrial projects and learn some advanced techniques such as Java SE, Spring Boot, Web development, and Distributed Architecture. You will also gain hands-on experience with real-world Java programs and enhance your resume, which will help you secure your dream job -
 Spring Project CourseThe Spring Project Course helps you quickly master key Spring modules, including Spring Boot, Spring Security, Spring Web MVC, Spring Data JPA, and more, through real-world projects. You'll gain essential skills and hands-on experience with web project development, enhancing your professional competence.
Spring Project CourseThe Spring Project Course helps you quickly master key Spring modules, including Spring Boot, Spring Security, Spring Web MVC, Spring Data JPA, and more, through real-world projects. You'll gain essential skills and hands-on experience with web project development, enhancing your professional competence. -
 Practical Web Project CourseThis course helps you build real-world web projects while deepening your understanding of Spring Framework, microservices, and web development fundamentals. You will also master the Front-End and Back-End of the Web, Framework Design and Project implementation which will accumulate your practical experience and enhance your coding skills.
Practical Web Project CourseThis course helps you build real-world web projects while deepening your understanding of Spring Framework, microservices, and web development fundamentals. You will also master the Front-End and Back-End of the Web, Framework Design and Project implementation which will accumulate your practical experience and enhance your coding skills. -
 Distributed System Project CourseIn combination with real-world PRDs, the distributed system course shows distributed systems architecture and microservices technology. You will learn how to design, develop and deploy distributed systems from scratch. Also, you will master the frequently asked interview questions including high availability, fault tolerance and asynchronous programming so that you can accumulate rich project experience.
Distributed System Project CourseIn combination with real-world PRDs, the distributed system course shows distributed systems architecture and microservices technology. You will learn how to design, develop and deploy distributed systems from scratch. Also, you will master the frequently asked interview questions including high availability, fault tolerance and asynchronous programming so that you can accumulate rich project experience. -
 Interview Crash CourseThis course will comprehensively improve your technical interview skills and help you prepare well for the interview. You will learn basic Java knowledge, Spring framework and other core technology. We will provide resume optimization, mock interviews and job guidance to improve your interview ability and job competitiveness.
Interview Crash CourseThis course will comprehensively improve your technical interview skills and help you prepare well for the interview. You will learn basic Java knowledge, Spring framework and other core technology. We will provide resume optimization, mock interviews and job guidance to improve your interview ability and job competitiveness.
-
-
Algorithm Courses
Algorithm Courses
-
 Master Algorithms and Java Data Structures for InterviewsWe offer a comprehensive Algorithm Training Program designed to significantly enhance your algorithm interview success rate. This course covers Java programming, data structures, and Object-Oriented Design (OOD). We will also help you strengthen your problem-solving skills through interactive learning and problem-solving exercises to efficiently tackle frequently asked algorithm interview questions.
Master Algorithms and Java Data Structures for InterviewsWe offer a comprehensive Algorithm Training Program designed to significantly enhance your algorithm interview success rate. This course covers Java programming, data structures, and Object-Oriented Design (OOD). We will also help you strengthen your problem-solving skills through interactive learning and problem-solving exercises to efficiently tackle frequently asked algorithm interview questions. -
 Crash Course in Algorithms and Data Structures for InterviewsCrash course in algorithms is designed to help beginners quickly get started, providing online lessons in algorithms and data structures. You will quickly grasp common questions in Java interviews and improve your problem-solving abilities. This course also helps the students prepare for interviews, achieve rapid algorithmic advancement, and gain comprehensive skills improvement.
Crash Course in Algorithms and Data Structures for InterviewsCrash course in algorithms is designed to help beginners quickly get started, providing online lessons in algorithms and data structures. You will quickly grasp common questions in Java interviews and improve your problem-solving abilities. This course also helps the students prepare for interviews, achieve rapid algorithmic advancement, and gain comprehensive skills improvement. -
 Java Basics CourseThe Java basics course helps beginners get started easily and quickly master fundamental Java syntax. Covering core knowledge for Java beginners, it helps students build a solid foundation for algorithms and boosts the efficiency of learning Java programming.
Java Basics CourseThe Java basics course helps beginners get started easily and quickly master fundamental Java syntax. Covering core knowledge for Java beginners, it helps students build a solid foundation for algorithms and boosts the efficiency of learning Java programming. -
 Introduction to Algorithms【2025】Experienced teachers teach you how to build a solid foundation for algorithms and combine practical skills and logical training to rapidly enhance your core algorithm skills. With the Drill coder platform, you will have a fundamental algorithm knowledge, practice algorithmic learning techniques efficiently as well as receive real-time feedback.
Introduction to Algorithms【2025】Experienced teachers teach you how to build a solid foundation for algorithms and combine practical skills and logical training to rapidly enhance your core algorithm skills. With the Drill coder platform, you will have a fundamental algorithm knowledge, practice algorithmic learning techniques efficiently as well as receive real-time feedback. -
 Algorithm Mastery CourseOur course is designed to guide students from beginner to advanced levels and is delivered by senior industry tutors to help you master algorithms from scratch. We incorporate complex algorithmic concepts into real interview questions by combining theory with practice for your rapid improvement during the training through an interactive learning method.
Algorithm Mastery CourseOur course is designed to guide students from beginner to advanced levels and is delivered by senior industry tutors to help you master algorithms from scratch. We incorporate complex algorithmic concepts into real interview questions by combining theory with practice for your rapid improvement during the training through an interactive learning method. -
 Advanced Algorithms CourseWe will help you master advanced algorithms and achieve a comprehensive algorithmic progression. By compiling the latest high-frequency interview questions from the leading companies, the industry experts will analyze the difficulties of the problems and conduct advanced training of algorithms for you. In addition, the practical training will enable you to grasp complex concepts and advance your algorithmic skills rapidly.
Advanced Algorithms CourseWe will help you master advanced algorithms and achieve a comprehensive algorithmic progression. By compiling the latest high-frequency interview questions from the leading companies, the industry experts will analyze the difficulties of the problems and conduct advanced training of algorithms for you. In addition, the practical training will enable you to grasp complex concepts and advance your algorithmic skills rapidly.
-
-
Data Engineering
Data Engineering View All About Data EngineeringCourse
-
Job Search Services
Job Search Services
-
 Direct Referral Channel for Big Tech OffersThe job referral service offers one-on-one training with experienced IT engineers, resume creation, and personalized interviews to help you quickly find your ideal job at a leading company and assist you in achieving your career goals.
Direct Referral Channel for Big Tech OffersThe job referral service offers one-on-one training with experienced IT engineers, resume creation, and personalized interviews to help you quickly find your ideal job at a leading company and assist you in achieving your career goals. -
 Resume Revision and Optimization ServiceThe experienced interviewers will personally edit and upgrade your resume by finding your competitiveness and highlights precisely. This course can also greatly help you gain more interview opportunities and get the offer from leading companies in the USA and other countries in the world.
Resume Revision and Optimization ServiceThe experienced interviewers will personally edit and upgrade your resume by finding your competitiveness and highlights precisely. This course can also greatly help you gain more interview opportunities and get the offer from leading companies in the USA and other countries in the world. -
 One-on-one Mock Interviews Service in EnglishOne-no-one mock interviews conducted in English with realistic replication of technical interview scenarios from top-tier companies will rapidly enhance your English communication skills in interviews. Combined with a detailed review of the interview process, you will master knowledge and skills for job interviews, improving your interview performance comprehensively.
One-on-one Mock Interviews Service in EnglishOne-no-one mock interviews conducted in English with realistic replication of technical interview scenarios from top-tier companies will rapidly enhance your English communication skills in interviews. Combined with a detailed review of the interview process, you will master knowledge and skills for job interviews, improving your interview performance comprehensively. -
 North America IT Career Planning and Consulting Services1v1 consultation with experts from top companies will help you create a personalized career development plan. Also, we will help you address challenges related to employment, job transitions, or career changes in the IT industry efficiently and develop a practical and achievable career path for Software Development Engineers (SDE), enabling you to break through career bottlenecks and achieve a major leap in your professional growth.
North America IT Career Planning and Consulting Services1v1 consultation with experts from top companies will help you create a personalized career development plan. Also, we will help you address challenges related to employment, job transitions, or career changes in the IT industry efficiently and develop a practical and achievable career path for Software Development Engineers (SDE), enabling you to break through career bottlenecks and achieve a major leap in your professional growth. -
 Partner Training Services of BQ InterviewYou will quickly improve the ability needed in BQ interviews through technique training. In addition, the BQ interview questions are tailored for you according to the key examination of companies in different areas and scales. You also have chances to get targeted exercise that will help you stand out from the crowd.
Partner Training Services of BQ InterviewYou will quickly improve the ability needed in BQ interviews through technique training. In addition, the BQ interview questions are tailored for you according to the key examination of companies in different areas and scales. You also have chances to get targeted exercise that will help you stand out from the crowd. -
 Interview Preparation and ReviewPersonalized interview preparation will be provided and you can prepare for your interview in combination with our interview question bank. Your interview performance will be highly optimized and the results will be effectively improved through online evaluation, technical interview, Guidance from the hiring manager and detailed interview feedback.
Interview Preparation and ReviewPersonalized interview preparation will be provided and you can prepare for your interview in combination with our interview question bank. Your interview performance will be highly optimized and the results will be effectively improved through online evaluation, technical interview, Guidance from the hiring manager and detailed interview feedback.
-
























